
Python 爬虫是当前热门的技术。正常情况下我们会在 Windows/MacOS 或者带图形界面的 Linux 上编写代码,之后往往会将代码部署到服务器上持续运行。
但是服务器 Linux 系统一般是不带图形界面的,本文将带你从头开始,在 Ubuntu Server 上搭建 Chrome + Selenium 环境。
安装 Python3+Pip3
在较新的 Ubuntu Server 发行版上(本文示例为 20.04 LTS),默认已经安装了 Python3,只需要手动安装 Pip3 即可。为了方便,以及避免依赖项的缺失,建议无论是否安装都手动运行一次:
# 安装 Python3
sudo apt-get install -y python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev libcurl4-openssl-dev
sudo apt-get install -y python3
# 安装 Pip3
sudo apt-get install -y python3-pip安装完成后可测试是否成功:
python3 --version
pip3 --version
如果正常输出把版本即证明已经安装成功。
安装 Selenium 库
Selenium 是一个综合性的项目,为web浏览器的自动化提供了各种工具和依赖包。另外,Selenium 为 W3C WebDriver specification(页面存档备份,存于互联网档案馆)提供了基础设施。
维基百科 – Selenium(软件)
做爬虫的很难避免使用 Selenium,特别是抓取动态网页,需要和 Javascrip 打交道时,用 Selenium 可以模拟用户的实际操作,获得更真实更可视化的数据。
上文安装 Pip3 的目的就是为了方便以后安装 Python 库:
# 安装 Selenium 库
pip3 install selenium
# 顺带安装日后常用的 requests 库
pip3 install requests进入 Python 交互环境,引入 Selenium,如果没有报错则说明安装成功。

安装 Chrome
最新版本的 Chrome 可从 Chrome 官网 下载。如果你使用 Windows 或 MacOS 访问,那么页面下载地址就是针对当前系统的,需要下拉到页面底部,选择不同平台:
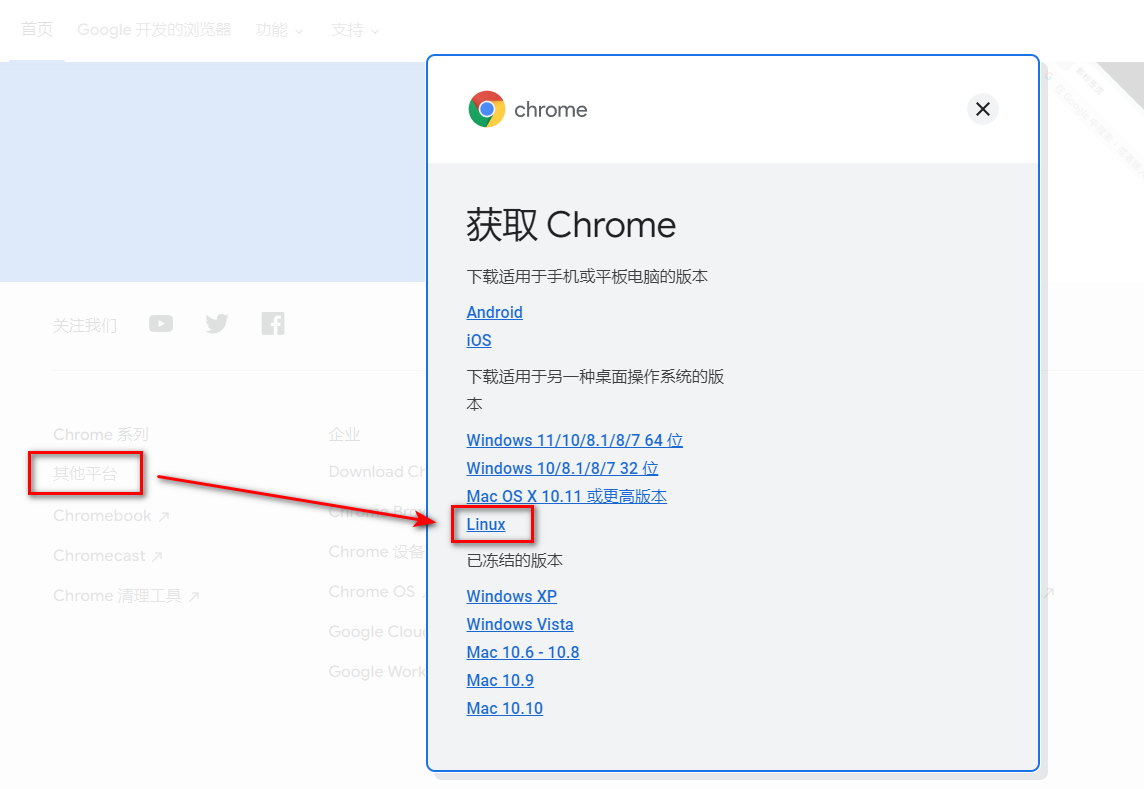
接着参考 Ubuntu 下用命令安装 deb 包 这篇文章安装 Chrome 。安装完成后也可以测试看是否成功:

顺利输出版本号,说明安装成功。记住这个版本号,下面我们要根据 Chrome 的版本号下载 ChromeDriver。
配置 ChromeDriver
WebDriver is an open source tool for automated testing of webapps across many browsers. It provides capabilities for navigating to web pages, user input, JavaScript execution, and more.
chromedriver.chromium.org
如果 Selenium 是指挥官,那么 ChromeDriver 就是执行命令的士兵,需要通过它才能调用浏览器(兵器)做事情,所以它的版本必须和系统上安装的 Chrome 的版本匹配。
ChromeDriver 下载地址:https://chromedriver.storage.googleapis.com/index.html
120 以上版本的 Chrome 需要在这里下载:Chrome for Testing availability
上文截图可看到,演示用的 Chrome 版本为 102.0.5005.61 ,所以我们也要选择该版本来下载。
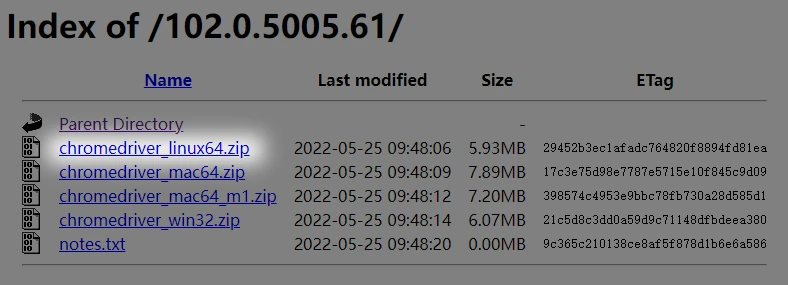
下载之后解压并移动到执行路径:
# 解压
unzip chromedriver_linux64.zip
# 添加执行权限
chmod +x chromedriver
# 移动 ChromeDriver 到执行路径
sudo mv ./chromedriver /usr/local/bin/chromedriver此时在命令行应该已经可以直接运行 ChromeDriver:

但是这还不够,要在 Python 程序中方便调用 ChromeDriver,我们可以将它的路径添加到环境变量中。
# 编辑 .profile 文件
vim ~/.profile
# 在结尾添加 PATH 路径,然后保存
export PATH="$PATH:/usr/local/bin/chromedriver"
# 使配置生效
source profile
# 查看环境变量
echo $PATH设置环境变量后,我们在 Python 代码中调用 ChromeDriver 就不用写完整路径:

使用“有头模式”
Selenium 抓取网页时可使用有头模式和无头模式。
在有头模式下,我们可以看到浏览器窗口被打开,程序所做的操作都是可以看见的;无头模式则不会有窗口,类似于后台运行。
但是既然有爬虫技术,那么同时也会有反爬虫技术,毕竟谁也不希望自己的数据被他人(甚至竞争对手)薅走。据称,Selenium 在运行时也会留下相应特征,相比有头模式,无头模式的特征更加明显,更容易被反爬技术识别。
不过在无界面的 Ubuntu Server 上运行有头模式会导致报错,因为 Chrome 无法绘制图形。此时我们可以借助第三方工具来创建虚拟桌面,从而欺骗 Selenium 继续运行。
Xvfb 在一个没有图像设备的机器上实现了 X11 显示服务的协议。它实现了其他图形界面都有的各种接口,但并没有真正的图形界面。所以当一个程序在 Xvfb 中调用图形界面相关的操作时,这些操作都会在虚拟内存里面运行,只不过你什么都看不到而已。
使用 Xvfb,我们就可以欺骗 Selenium 或者 Puppeteer,让它以为自己运行在一个有图形界面的系统里面,这样一来就能够正常使用有头模式了。
首先安装 Xvfb:
sudo apt-get update
sudo apt-get install xvfb接着编写一段 Python 测试代码:
import time
from selenium.webdriver import Chrome
driver = Chrome('chromedriver')
driver.get('https://bot.sannysoft.com/')
time.sleep(5)
driver.save_screenshot('screenshot.png')
driver.close()
print('运行完成')因为没有图形界面,直接运行这段代码会报错。
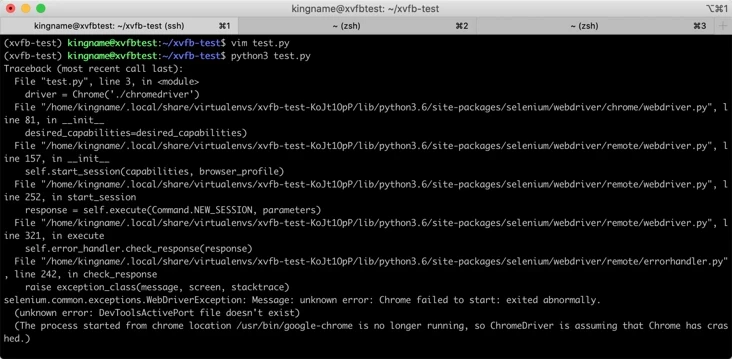
但是在运行这段代码的命令前面加上 xvfb-run 就能够顺利运行:
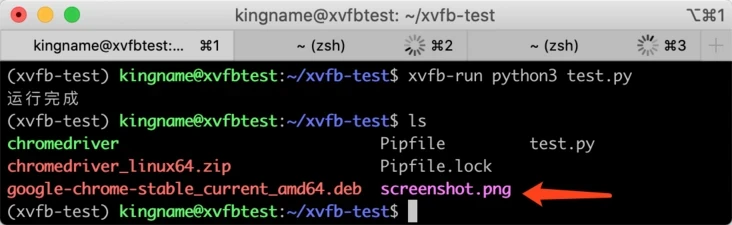
至此 Ubuntu Server 上的 Chrome + Selenium 环境已搭建完成,接下来就尽情写代码玩耍吧!
参考资料:



